
News Anyway
The latest news and views from around the world
- Achieving Excellence in Accounting: Lessons for Successful Professionals
- Kasra Dash Opens TaxBite Accountants Manchester – Lower Byrom St, Manchester M3 4AL
- CPA John Savignano on the 15 Traits Accountants Need To Succeed
- 360 ACCOUNTANTS ADDRESS HUGE FINANCIAL BURDEN FACING BUSINESSES
- Want to find the correct accountant for your business?
- YORKSHIRE ACCOUNTANTS ANNOUNCE NEW WEALTH MANAGEMENT PARTNERSHIP





Tosçelik Spiral Boru, an esteemed division of Tosyalı, Türkiye’s dominant …

Custom backgrounds for your office team are not difficult to …

Change is a constant in today’s dynamic business landscape, and …
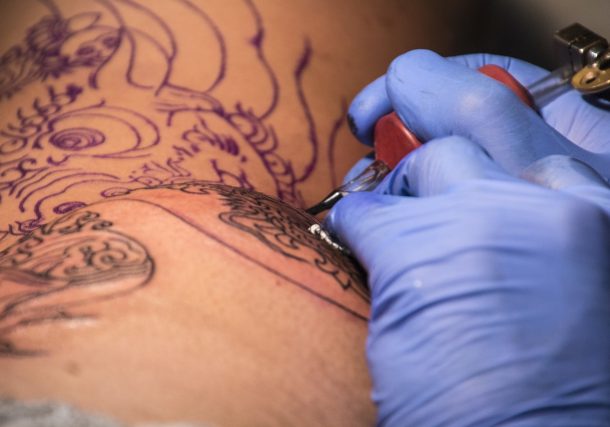
Amsterdam, 16-4-2024 – Tattoo culture has long been thriving in …
Technology
Business
Health
Lifestyle
Recent News
View AllHave you ever wondered how products in your home are made so quickly and precisely? Robotics programming is …
ThinkOTB, a marketing agency based in Leeds, has been selected to assist Woolroom, a prominent wool bedding retailer …
In a world where credit rules supreme, having a high credit score is more vital than ever. Unfortunately, …
An obscure number plate rule could lead to fines of up to £1,000 for drivers, with crime rates …

Today’s discussion around menstrual health is evolving from mere convenience to encompass broader themes of sustainability and inclusivity. …

Clear and effective communication is key to success in today’s corporate environment. Whether for a boardroom presentation, a …